博客网站的结构很简单,大概只有三种页面类型:链接到文章和页面的主页、文章页面、独立页面。
如果要求不高,其中文章页面、独立页面可以合并成一个页面类型。因此最多只需要写2个Python脚本就够了。
创建主页文件.py
主页文件只有两个功能:显示博客名称、显示和链接文章或其它页面。
但是首先,必须要输入数据才能生成吧?因此需要一个字符串变量和一个列表变量,在里面填写数据:
# 数据输入
博客标题 = ''
文章列表 = [
''
]然后就可以创建index.html文件了,方便生成页面:
# 数据输入
博客标题 = ''
文章列表 = [
''
]
# 创建文件
index = open('index.html', 'w', encoding='utf-8')通常来说,HTML头部的部分是可以一成不变的,因此只需要把一些字符用变量替代就可以了:
# 数据输入
博客标题 = ''
文章列表 = [
''
]
# 创建文件
index = open('index.html', 'w', encoding='utf-8')
# 生成头部部分
index.write(
f'''
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0, minimum-scale=0.5, maximum-scale=2.0, user-scalable=yes" />
<title>{博客标题}</title>
</head>
<body>
<h1>{博客标题}</h1>
<hr>
''')然后就可以生成页面的主体,最简单的方法是使用for遍历文章列表,中间用再把一些字符用变量替代,中间用<hr>分割:
# 数据输入
博客标题 = ''
文章列表 = [
''
]
# 创建文件
index = open('index.html', 'w', encoding='utf-8')
# 生成头部部分
index.write(
f'''
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0, minimum-scale=0.5, maximum-scale=2.0, user-scalable=yes" />
<title>{博客标题}</title>
</head>
<body>
<h1>{博客标题}</h1>
<hr>
''')
# 生成文章列表
for text in 文章列表:
index.write(
f'''
<h2><a href="{text}.html">{text}</a></h2>
<hr>
''')最后,再来一个华丽的收尾:
# 数据输入
博客标题 = ''
文章列表 = [
''
]
# 创建文件
index = open('index.html', 'w', encoding='utf-8')
# 生成头部部分
index.write(
f'''
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0, minimum-scale=0.5, maximum-scale=2.0, user-scalable=yes" />
<title>{博客标题}</title>
</head>
<body>
<h1>{博客标题}</h1>
<hr>
''')
# 生成文章列表
for text in 文章列表:
index.write(
f'''
<h2><a href="{text}.html">{text}</a></h2>
<hr>
''')
# 生成页尾部分
index.write(
f'''
</body>
</html>
''')输入以下数据时,效果是这样的:
博客标题 = 'Pinpe 的博客'
文章列表 = [
'一个月的网站更新日志',
'配置对话式关于页面',
'【多图预警】国庆节我去哪了?'
]
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0, minimum-scale=0.5, maximum-scale=2.0, user-scalable=yes" />
<title>Pinpe 的博客</title>
</head>
<body>
<h1>Pinpe 的博客</h1>
<hr>
<h2><a href="一个月的网站更新日志.html">一个月的网站更新日志</a></h2>
<hr>
<h2><a href="配置对话式关于页面.html">配置对话式关于页面</a></h2>
<hr>
<h2><a href="【多图预警】国庆节我去哪了?.html">【多图预警】国庆节我去哪了?</a></h2>
<hr>
</body>
</html>
创建文章或页面文件.py
需要一个单行字符串变量和一个多行字符串变量:
# 数据输入
文章或页面标题 = ''
内容 = '''
'''创建的文件名就是文章/页面标题:
# 数据输入
文章或页面标题 = ''
内容 = '''
'''
# 创建文件
page = open(f'{文章或页面标题}.html', 'w', encoding='utf-8')然后更加简单了,只需要对变量替换就可以实现:
# 数据输入
文章或页面标题 = ''
内容 = '''
'''
# 创建文件
page = open(f'{文章或页面标题}.html', 'w', encoding='utf-8')
# 生成页面
page.write(
f'''
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0, minimum-scale=0.5, maximum-scale=2.0, user-scalable=yes" />
<title>{文章或页面标题}</title>
</head>
<body>
<h1>{文章或页面标题}</h1>
<hr>
{内容}
</body>
</html>
''')输入以下数据时,效果是这样的:
文章或页面标题 = '外国中文研究史'
内容 = '''
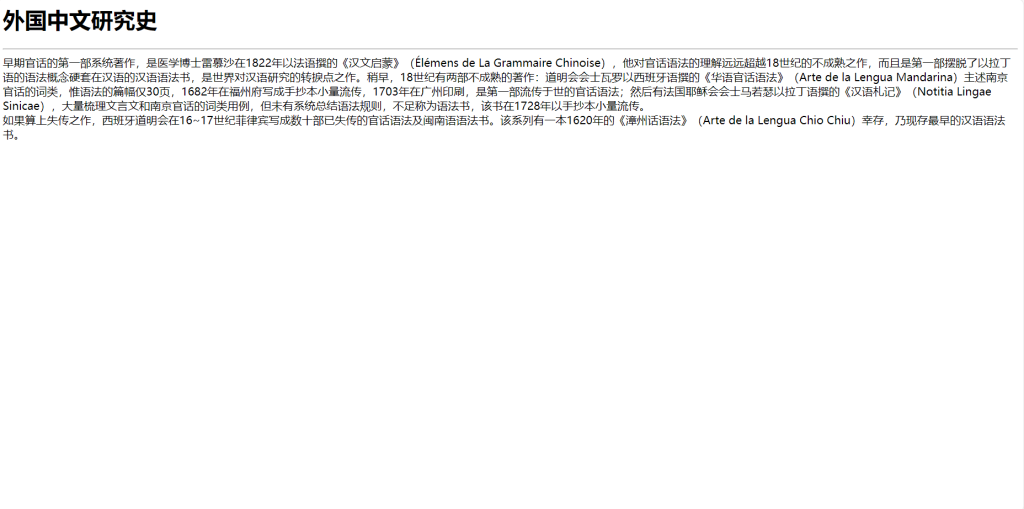
早期官话的第一部系统著作,是医学博士雷慕沙在1822年以法语撰的《汉文启蒙》(Élémens de La Grammaire Chinoise),他对官话语法的理解远远超越18世纪的不成熟之作,而且是第一部摆脱了以拉丁语的语法概念硬套在汉语的汉语语法书,是世界对汉语研究的转捩点之作。稍早,18世纪有两部不成熟的著作:道明会会士瓦罗以西班牙语撰的《华语官话语法》(Arte de la Lengua Mandarina)主述南京官话的词类,惟语法的篇幅仅30页,1682年在福州府写成手抄本小量流传,1703年在广州印刷,是第一部流传于世的官话语法;然后有法国耶稣会会士马若瑟以拉丁语撰的《汉语札记》(Notitia Lingae Sinicae),大量梳理文言文和南京官话的词类用例,但未有系统总结语法规则,不足称为语法书,该书在1728年以手抄本小量流传。<br>
如果算上失传之作,西班牙道明会在16~17世纪菲律宾写成数十部已失传的官话语法及闽南语语法书。该系列有一本1620年的《漳州话语法》(Arte de la Lengua Chio Chiu)幸存,乃现存最早的汉语语法书。
'''
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0, minimum-scale=0.5, maximum-scale=2.0, user-scalable=yes" />
<title>外国中文研究史</title>
</head>
<body>
<h1>外国中文研究史</h1>
<hr>
早期官话的第一部系统著作,是医学博士雷慕沙在1822年以法语撰的《汉文启蒙》(Élémens de La Grammaire Chinoise),他对官话语法的理解远远超越18世纪的不成熟之作,而且是第一部摆脱了以拉丁语的语法概念硬套在汉语的汉语语法书,是世界对汉语研究的转捩点之作。稍早,18世纪有两部不成熟的著作:道明会会士瓦罗以西班牙语撰的《华语官话语法》(Arte de la Lengua Mandarina)主述南京官话的词类,惟语法的篇幅仅30页,1682年在福州府写成手抄本小量流传,1703年在广州印刷,是第一部流传于世的官话语法;然后有法国耶稣会会士马若瑟以拉丁语撰的《汉语札记》(Notitia Lingae Sinicae),大量梳理文言文和南京官话的词类用例,但未有系统总结语法规则,不足称为语法书,该书在1728年以手抄本小量流传。<br>
如果算上失传之作,西班牙道明会在16~17世纪菲律宾写成数十部已失传的官话语法及闽南语语法书。该系列有一本1620年的《漳州话语法》(Arte de la Lengua Chio Chiu)幸存,乃现存最早的汉语语法书。
</body>
</html>
文件下载
所有使用的脚本:
这个方式我之前想过,但是后来弃坑了。当时想搭建一个 API 接口站点,但是网络上流传的含后台的源码(php程序)我的虚拟主机用不了,我就花费了一点心思用 Python 写了个简陋的后台(当然每次使用还是得打开代码编辑器)。
这个方法固然好,但是如果作为需要发布上线的网页,每次都需要打开服务器后台更新前端 HTML 文件就有点麻烦。
这边有个想法,就是找一台支持 Python 的服务器,将上面代码中的封装成接口,使之可以像网上出现的类似 QQ 头像查询接口一样,用 get/post 请求,让 Python 在服务器后台自动操作更新文件(当然为了避免接口暴露,也可以添加一点验证,如设置一个参数接收全文和某段字符串拼接结果的 MD5 摘要)。在此基础上还可以用一些窗口框架写一个简陋的后台程序,方便本地操作。
本评论仅作建议,实际可行性未知,而本人确实无啥本事(重要的是没钱折腾)。如果作者可以实践一下,并给出进一步的建议,那就太好了。
可以的,感觉有点难